Synthesis AI’s Human API: Outputs
Overview
The Human API is a data generating service that can create millions of labeled images of humans with a specifiable variety of sexes, ethnicities, ages, expressions, eye gazes, hair, hats, glasses, and more.
A request (also known as a “job”) is typically submitted by using a command line client application provided by Synthesis AI, and a job ID is returned. This job ID is referenced when the callback is returned, notifying the user that the job and all of its tasks have completed.
Some key terminology: a job has many tasks (aka scenes) associated with it. Each task has many assets, which include both text and binary metadata, like an EXR, metadata.jsonl, and *.info.json, and optionally several extracted, standalone binary images from the EXR channels like rgb, segments, depth, normals, and alpha images (example). More information on how to download all of these files via API exists at Asset Download API.
For each task, the only four unique asset types are EXR (a multi-channel OpenEXR file), *.mediapipe_dense.obj (read more), *.sai_dense.obj (read more), and *.info.json (computed values for each task not included at image request time). The other PNG & TIF files are extracted from layers in the EXR.
The metadata.jsonl file is also unique, but typically contains every task in a single file (unless requested differently).
We provide a synthesisai library in Python for parsing all of the output files.
Finally, there is an example of complete output of a single scene/task in the documentation appendix.
Metadata JSON Lines File
The metadata is the settings for each image made at request time, like pose of camera, lighting setup, and face attributes. These are simply what were requested at job creation time, so this document does not go into additional detail.
Note that is a JSON lines file, and that each line contains the full json that fully represents the scene. In the example below, "render_id":188 means that this line corresponds to 188.exr/188.info.json.
The value for version in each line of metadata.jsonl is incremented if there are structural changes to the format of the file, so you can write code that targets a specific version and issue warnings or errors on an unexpected version.
...
{
"api": 0,
"version": "1.3",
"task_id": "94baabeb-677d-467d-9659-5a98b7df1e26",
"render_id": 188,
"render": {
"resolution": {
"w": 512,
"h": 512
},
"noise_threshold": 0.017,
"engine": "vray",
"denoise": true
},
"scene": {
"id": 95,
"arms": {
"left": {
"enabled": false,
"elbow_yaw": 0,
"elbow_roll": 0,
"elbow_pitch": 50,
"held_object": "none",
"hand_gesture": "relaxed_spread",
"held_object_pose_seed": 0
},
"right": {
"enabled": false,
"elbow_yaw": 0,
"elbow_roll": 0,
"elbow_pitch": 50,
"held_object": "none",
"hand_gesture": "relaxed_spread",
"held_object_pose_seed": 0
}
},
"body": {
"height": "shorter",
"enabled": true,
"fat_content": "median"
},
"agent": {
"style": "00021_Yvonne004",
"enabled": false,
"position_seed": 0
},
"camera": {
"nir": {
"enabled": false,
"intensity": 4,
"size_meters": 1
},
"location": {
"depth_meters": 1,
"vertical_angle": 0,
"offset_vertical": 0,
"horizontal_angle": 0,
"offset_horizontal": 0
},
"specifications": {
"focal_length": 28,
"sensor_width": 33,
"lens_shift_vertical": 0,
"lens_shift_horizontal": 0,
"window_offset_vertical": 0,
"window_offset_horizontal": 0
}
},
"version": 0,
"clothing": {
"type": "1",
"enabled": true,
"variant": "3"
},
"accessories": {
"mask": {
"style": "none",
"variant": "0",
"position": "2"
},
"glasses": {
"style": "female_butterfly_sunglasses",
"metalness": 0,
"lens_color": "gray",
"transparency": 1,
"lens_color_rgb": [
158,
163,
167
]
},
"headwear": {
"style": "none"
},
"headphones": {
"style": "none"
}
},
"environment": {
"hdri": {
"name": "lauter_waterfall",
"rotation": 0,
"intensity": 0.75
},
"lights": [
{
"color": [
255,
255,
255
],
"rotation": [
0,
0,
0
],
"intensity": 0,
"size_meters": 0.25,
"distance_meters": 1.5
}
],
"geometry": "none",
"location": {
"id": 0,
"enabled": false,
"facing_direction": 0,
"head_position_seed": 0,
"indoor_light_enabled": false
}
},
"facial_attributes": {
"gaze": {
"vertical_angle": 0,
"horizontal_angle": 0
},
"hair": {
"color": "light_ash_blonde",
"style": "layered_01",
"color_seed": 0,
"relative_length": 1,
"relative_density": 1
},
"head_turn": {
"yaw": 0,
"roll": 0,
"pitch": 0
},
"expression": {
"name": "none",
"intensity": 0.75
}
},
"identity_metadata": {
"id": 95,
"age": 25,
"sex": "female",
"ethnicity": "black",
"height_cm": 160,
"weight_kg": 80,
"height_label": "shorter",
"fat_content_label": "median"
}
}
}
...*.info.json File
The *.info.json files represent computed values for each task, not fully known nor included at job request time. See also: example *.info.json in appendix. We also provide a synthesisai library in Python for parsing this file.
Contents
Each info json file contains *computed* information about the scene it’s numbered with (e.g. 11.info.json is for 11.exr/11.rgb.png):
- Pupil Coordinates
- Facial Landmarks (iBug 68-like)
- Camera Settings
- Eye Gaze
- Segmentation Values
Several body landmark systems are supported:
- Kinectv2 Kinectv2 Body Joints Documentation
- Coco
- Mediapipe
- mpeg4 Reference Table
See the Landmarks section below for more information.
Coordinate System
It’s important to note the several different axes that are referenced. We use a right-hand coordinate system. The world and camera axes are aligned Y-Up, X-Right, with negative Z pointing forward. At zero rotation, the head’s axes align with world axes, with it looking along the +ve Z-axis, as shown below.

Pupil Coordinates
3D pupil coordinates are available in the camera view axes, world axes, and 2D screen pixel coordinates.
-
screen_space_pos:
The u,vx,y pixel coordinates of the pupils, in % of the width and height of the full image. This value is derived from the scene generation application by using a camera-UV projection method to map point positions into a “zero to one” UV space that matches screen space. -
camera_space_pos:
A point’s 3D coordinates in the camera’s reference frame. This value is calculated by multiplying the camera extrinsic matrix (world2cam 4x4 transformation matrix) with the point’s world space coordinates. -
world_space_pos:
The 3D coordinates of a point in the world reference frame. These values are provided directly by the scene generation application.
An example is:
"pupil_coordinates": {
"pupil_left": {
"screen_space_pos": [
0.5784899592399597,
0.5743290781974792
],
"camera_space_pos": [
0.03564847633242607,
-0.03375868871808052,
-1.3762997388839722
],
"distance_to_camera": 1.3771750926971436,
"world_space_pos": [
0.030104853212833405,
0.27054131031036377,
0.10770561546087265
]
},
"pupil_right": {
"screen_space_pos": [
0.44264423847198486,
0.525549054145813
],
"camera_space_pos": [
0.03564847633242607,
-0.03375868871808052,
-1.3762997388839722
],
"distance_to_camera": 1.3855191469192505,
"world_space_pos": [
0.030104853212833405,
0.27054131031036377,
0.10770561546087265
]
}
}
Camera
Computed camera information is output as follows:
-
intrinsics:
The camera pinhole matrix, used by many libraries like in opencv. It is defined by:[[fx, 0, cx],[0, fy, cy],[0, 0, 1 ]],
wherefx,fy=focal length in pixels andcx,cy=principal point (center) of the image. -
field_of_view: Vertical and horizontal field of view, provided in radians. -
focal_length_mm: Essentially, the magnification/power of the lens. -
sensor width_mm & height_mm: Physical measurement of the dimensions of the camera sensor's active pixel area. -
transform_world2cam&transform_cam2world: Rigid transformation matrices (rotation+translation) between world and camera coordinate systems. Offered in two formats, a 4x4 matrix and a translation with a rotation quaternion. They are both offered to reduce floating point math rounding errors. The world2cam transform is used to convert a point in world coordinates to camera coordinates.
An example is:
"camera": {
"intrinsics": [
[
1551.5151515151515,
0.0,
256.0
],
[
0,
1551.5151515151515,
256.0
],
[
0,
0,
1.0
]
],
"field_of_view": {
"y_axis_rads": 0.32705323764198635,
"x_axis_rads": 0.32705323764198635
},
"focal_length_mm": 100.0,
"transform_world2cam": {
"mat_4x4": [
[
0.9965137705108044,
0.0,
0.0834284434850595,
-0.0033371377394023813
],
[
0.0,
1.0,
0.0,
-0.3043
],
[
-0.0834284434850595,
0.0,
0.9965137705108045,
-1.4811182508204321
],
[
0.0,
0.0,
0.0,
1.0
]
],
"translation_xyz": [
-0.0033371377394023813,
-0.3043,
-1.4811182508204321
],
"quaternion_wxyz": [
0.0,
0.041750625679117394,
0.0,
0.9991280624901906
],
"euler_xyz": [
0.0,
4.785660300000001,
0.0
]
},
"sensor": {
"width_mm": 33.0,
"height_mm": 33.0
},
"transform_cam2world": {
"mat_4x4": [
[
0.9965137705108045,
0.0,
-0.08342844348505951,
-0.12024188657185686
],
[
0.0,
1.0,
0.0,
0.3043
],
[
0.08342844348505951,
0.0,
0.9965137705108045,
1.47623314490473
],
[
0.0,
0.0,
0.0,
1.0
]
],
"translation_xyz": [
-0.12024188657185686,
0.3043,
1.47623314490473
],
"quaternion_wxyz": [
0.0,
-0.041750625679117394,
0.0,
0.9991280624901906
],
"euler_xyz": [
0.0,
-4.785660300000001,
0.0
]
}
}
Camera Intrinsics Directionality
Our camera intrinsic matrix is output with +x right, +y downwards, +z away from camera. This aligns with OpenCV standards, which has its origins in 2D computer standards.
However, all of our 3D landmark points are output with +x right, +y upwards, +z towards the camera. This aligns with 3D Graphics programs and openGL, which draw from 3D computer standards.
Here’s the code used to output the intrinsic matrix:
camFocal = float(focal_length) # focal_length from 3d renderer
sensor_x = float(aperture[0]) # sensor_width equivalent from 3d renderer
resx = float(resolution[0]) # resolution_x from 3d renderer
resy = float(resolution[1]) # resolution_y from 3d renderer
shift_x = 0.0 # horizontal_win_offset from 3d renderer
shift_y = 0.0 # vertical_win_offset from 3d renderer
skew = 0.0 # Only rectangular pixels currently supported
fx = camFocal * (resx / sensor_x) # Focal length in pixels
fy = fx # ideal camera has square pixels, so fx=fy
cx = resx / 2.0 - shift_x * resx
cy = resy / 2.0 + shift_y * resy
sensor_y = sensor_x * (resy / resx)
fovx = 2.0 * np.arctan( (sensor_x / 2.0) / camFocal )
fovy = 2.0 * np.arctan( (sensor_y / 2.0) / camFocal )
# OpenCV intrinsics
camIntrinsics = [[fx, skew, cx], [skew, fy, cy], [0, 0, 1.0]]
# OpenGL intrinsics, not output
camIntrinsics_OGL = [[fx, skew, cx], [-skew, -fy, -cy], [0, 0, -1.0]]
In order to use the intrinsic matrix in combination with the 3d landmarks, we have to convert the output camera intrinsics from openCV back to the openGL orientation.
Eye Gaze
Eye gaze is computed for convenience as angles from the head’s point of view, as well as a vector in world coordinate space.
-
face_attributes.gaze.vertical(horizontal)_angle:The input value selected by the user for the image generation process.
-
gaze_values.left(right)_eye.vertical(horizontal)_angles:A computed value that accounts for differences in default ("resting") eye placement from human to human. A dot product of {0,0,1} with a vector: the centroid of the eye volume, to the location of the pupil in world coordinates, but calculated pre-deformation of the head due to head turn.
-
gaze_values.left(right)_eye.gaze_vector:The centroid of the eye volume, to the location of the pupil in world coordinates, but calculated post-deformation of the head due to head turn. Also affected by differences in default ("resting") eye placement from human to human.
An example is:
"gaze_values": {
"eye_left": {
"horizontal_angle": -8.255141258239746,
"gaze_vector": [
0.377139687538147,
-0.2047073394060135,
-0.9032500386238098
],
"vertical_angle": 13.074122428894043
},
"eye_right": {
"horizontal_angle": -8.255141258239746,
"gaze_vector": [
0.377139687538147,
-0.2047073394060135,
-0.9032500386238098
],
"vertical_angle": 13.074122428894043
}
}
Head Rotation Matrix
The head_turn values (pitch/yaw/roll) applied to the head are used as the rotation parameters of the head2world and head2cam transforms.
When we create head turns, we do it in as anatomically correct a way as possible, in order to match what real life data would look like. One result is a non-rigid deformation of the head — some parts of the face shift more than others because the neck is a joint, and humans simply do not turn from center of their heads in perfectly precise directions.
An example is:
"head_transform": {
"transform_head2world": {
"mat_4x4": [
[
0.9999998807907104,
3.795717518073616e-09,
-1.1272692113095673e-08,
0.3649168312549591
],
[
-1.5658536689500124e-09,
0.9653543829917908,
-0.26094332337379456,
1.2944992780685425
],
[
1.2986717257135183e-09,
0.2609434723854065,
0.9653540849685669,
0.03487874194979668
],
[
0.0,
0.0,
0.0,
1.0
]
]
},
"transform_head2cam": {
"mat_4x4": [
[
0.9999998807907104,
3.795717457243046e-09,
-1.1272692125404367e-08,
-0.004083126783370972
],
[
-1.0364290025067905e-09,
0.9968155230876654,
0.07974584519386402,
0.010149104736181913
],
[
1.7505030381278185e-09,
-0.07974580536604059,
0.9968151922764701,
-0.591210747030589
],
[
0.0,
0.0,
0.0,
1.0
]
]
}
}
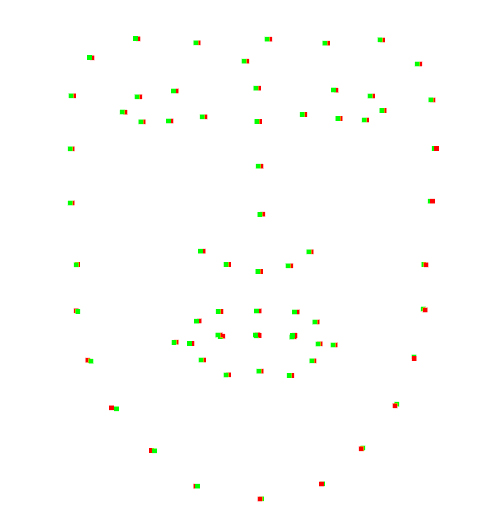
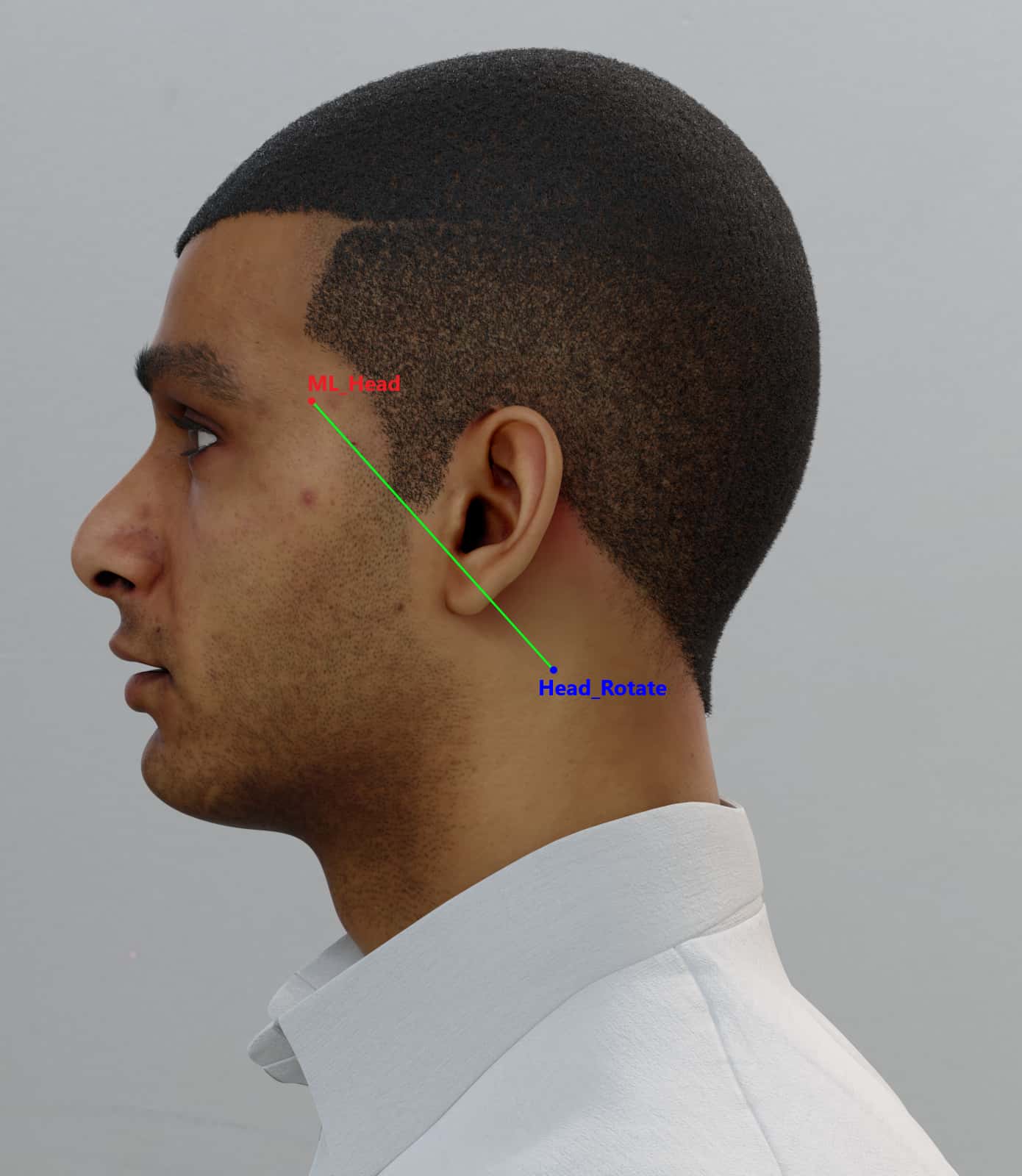
Visual examples of head rotation limits:







Body Segmentation
The body segmentation mapping values explain which pixel value represents each area of the body.
The segmentation output file (accessed with --assets segments in the CLI) is a PNG file (example) containing different pixel values for each area of the face. Each *.info.json (example) file contains the mapping of what pixel value represents each area. Our synthesisai library contains python functions for parsing this file.
{kind=link}


Face segmentation mapping:
"segments_mapping": {
"background":0,
"brow":3,
"cheek_left":4,
"cheek_right":5,
"chin":6,
"ear_left":8,
"ear_right":9,
"eye_left":10,
"eye_right":11,
"eyelashes":12,
"eyelid":13,
"eyes":14,
"forehead":15,
"hair":17,
"head":18,
"jaw":21,
"jowl":22,
"lip_lower":23,
"lip_upper":24,
"mouth":26,
"mouthbag":27,
"nose":30,
"nose_outer":31,
"nostrils":32,
"smile_line":34,
"teeth":35,
"temples":36,
"tongue":37,
"undereye":38,
"eyebrows":89,
"pupil_left":90,
"pupil_right":91,
"eyelashes_left":92,
"eyelashes_right":93,
"eyelid_left":92,
"eyelid_right":93,
"eyebrow_left":94,
"eyebrow_right":95,
"undereye_left":99,
"undereye_right":100,
"sclera_left":101,
"sclera_right":102,
"cornea_left":103,
"cornea_right":104
}Full body segmentation mapping:
"segments_mapping": {
"default":0,
"background":0,
"beard":1,
"body":2,
"brow":3,
"cheek_left":4,
"cheek_right":5,
"chin":6,
"clothing":7,
"ear_left":8,
"ear_right":9,
"eye_left":10,
"eye_right":11,
"eyelashes":12,
"eyelid":13,
"eyes":14,
"forehead":15,
"glasses":16,
"hair":17,
"head":18,
"headphones":19,
"headwear":20,
"jaw":21,
"jowl":22,
"lip_lower":23,
"lip_upper":24,
"mask":25,
"mouth":26,
"mouthbag":27,
"mustache":28,
"neck":29,
"nose":30,
"nose_outer":31,
"nostrils":32,
"shoulders":33,
"smile_line":34,
"teeth":35,
"temples":36,
"tongue":37,
"undereye":38,
"eyebrows":89,
"torso_lower_left":40,
"torso_lower_right":41,
"torso_mid_left":42,
"torso_mid_right":43,
"torso_upper_left":44,
"torso_upper_right":45,
"arm_lower_left":46,
"arm_lower_right":47,
"arm_upper_left":48,
"arm_upper_right":49,
"hand_left":50,
"hand_right":51,
"finger1_mid_bottom_left":52,
"finger1_mid_bottom_right":53,
"finger1_mid_left":54,
"finger1_mid_right":55,
"finger1_mid_top_left":56,
"finger1_mid_top_right":57,
"finger2_mid_bottom_left":58,
"finger2_mid_bottom_right":59,
"finger2_mid_left":60,
"finger2_mid_right":61,
"finger2_mid_top_left":62,
"finger2_mid_top_right":63,
"finger3_mid_bottom_left":64,
"finger3_mid_bottom_right":65,
"finger3_mid_left":66,
"finger3_mid_right":67,
"finger3_mid_top_left":68,
"finger3_mid_top_right":69,
"finger4_mid_bottom_left":70,
"finger4_mid_bottom_right":71,
"finger4_mid_left":72,
"finger4_mid_right":73,
"finger4_mid_top_left":74,
"finger4_mid_top_right":75,
"finger5_mid_bottom_left":76,
"finger5_mid_bottom_right":77,
"finger5_mid_left":78,
"finger5_mid_right":79,
"finger5_mid_top_left":80,
"finger5_mid_top_right":81,
"nails_left":82,
"nails_right":83,
"leg_lower_left":84,
"leg_lower_right":85,
"leg_upper_left":86,
"leg_upper_right":87,
"foot_left":88,
"foot_right":89,
"pupil_left":90,
"pupil_right":91,
"eyelashes_left":92,
"eyelashes_right":93,
"eyelid_left":92,
"eyelid_right":93,
"eyebrow_left":94,
"eyebrow_right":95,
"glasses_frame":96,
"glasses_lens_left":97,
"glasses_lens_right":98,
"undereye_left":99,
"undereye_right":100,
"sclera_left":101,
"sclera_right":102,
"cornea_left":103,
"cornea_right":104
}Clothing Segmentation
The clothing segmentation mapping values explain which pixel value represents each part of the outfit.
The clothing segmentation output file (accessed with --assets clothing-segments in the CLI) is a PNG file (example) containing different pixel values for each outfit piece. Each *.info.json (example) file contains the mapping of what pixel value represents each area. Our synthesisai library contains python functions for parsing this file.
{kind=link}

Example image clothing segmentation mapping
"clothing_segments_mapping": {
"background": 0,
"long sleeve outerwear": 1,
"shoe": 2,
"short sleeve shirt": 3,
"trousers": 4
}Full clothing segmentation mapping:
"clothing_segments_mapping": {
"background":0,
"bandana":1,
"belt":2,
"cap":3,
"glove":4,
"harness":5,
"hat":6,
"long sleeve dress":7,
"long sleeve outerwear":8,
"long sleeve shirt":9,
"scarf":10,
"shoe":11,
"short sleeve dress":12,
"short sleeve outerwear":13,
"short sleeve shirt":14,
"shorts":15,
"sling":16,
"sling dress":17,
"sock":18,
"trousers":19,
"vest":20,
"vest dress":21
}Landmarks
Facial Landmarks
Our facial landmarks output are placed in *similar*, but not exactly the same as, the iBug 68 landmark locations. The primary difference is that occluded landmarks are placed corresponding to their actual 3D location. I.e., occluded landmarks are not “displaced” to match visible face contours..


Sample code for parsing these landmarks in Python is at: https://github.com/Synthesis-AI-Dev/project-landmarks-to-image
An example is:
"landmarks": [
{
"screen_space_pos": [
0.382,
0.49
],
"ptnum": 0,
"camera_space_pos": [
-0.05711684003472328,
0.004818509332835674,
-1.467186450958252
],
"distance_to_camera": 1.4683057069778442,
"world_space_pos": [
-0.05475452169775963,
0.30911850929260254,
0.009396456182003021
]
},
...
]
Mediapipe Face Landmarks (Enterprise Pricing)
MediaPipe Face Mesh is a solution that estimates 468 3D face landmarks.
We provide MediaPipe Face Landmarks on every render of our output in an .obj file, for customers who sign up for an Enterprise Pricing plan.
You can find more information about the face landmark model in this paper.

Check our documentation appendix for a sample mediapipe_dense.obj file
SAI 4,000+ Dense Landmarks: (Enterprise Pricing)
For avatar recreation use-cases, we provide our dense landmark model in the .obj format, with over 4,000 3D landmarks. This is available for customers who sign up for an Enterprise Pricing plan.

Check our documentation appendix for a sample sai_dense.obj file
Azure Kinect
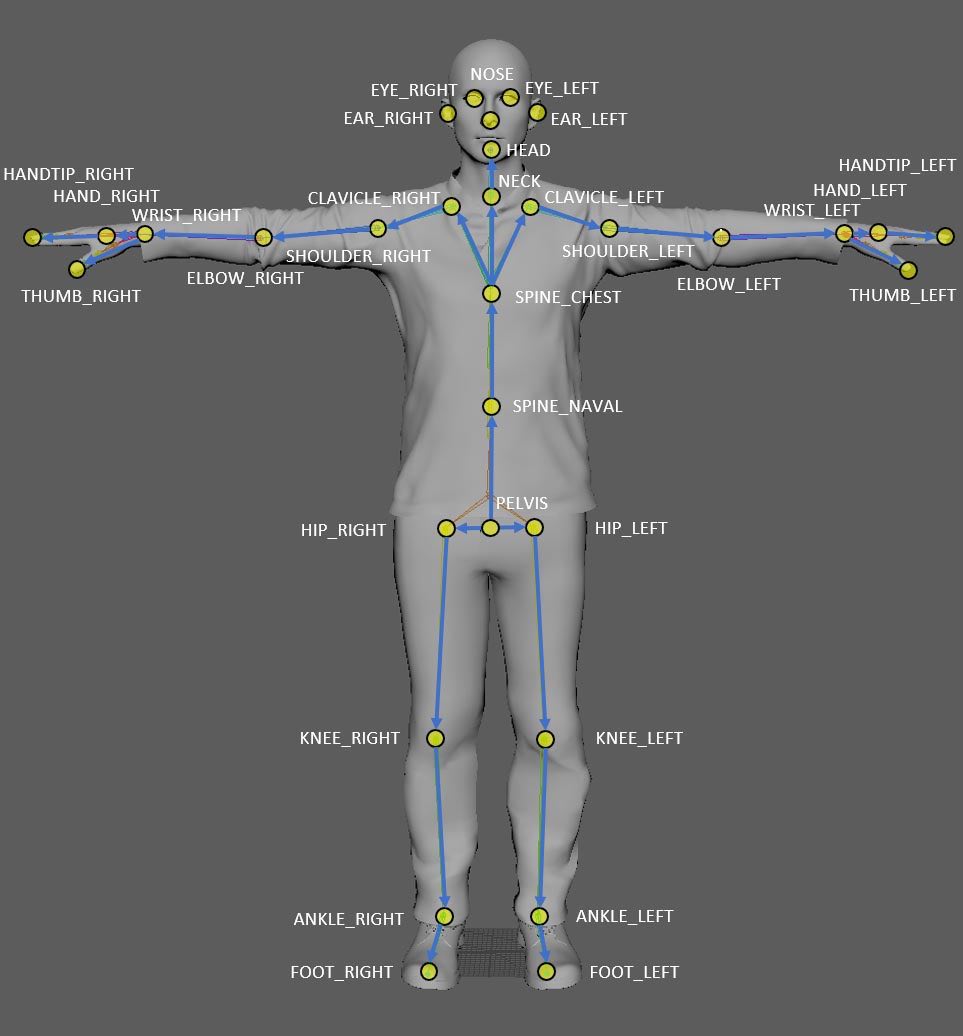
Azure Kinect is a spatial computing developer kit created by Microsoft with sophisticated computer vision and speech models, advanced AI sensors, and a range of powerful SDKs that can be connected to Azure cognitive services.
Here is an example of Azure Kinect's joint hierarchy:
An example is:
{
"kinect_v2": [{
"screen_space_pos": [
-0.5749289136970677,
1.4779910880511973
],
"name": "HAND_RIGHT",
"in_frustum": false,
"world_space_pos": [
-0.6166318655014038,
1.069034218788147,
0.07687398791313171
],
"camera_space_pos": [
-0.6098259687423706,
-0.5548314452171326,
-0.2836587429046631
],
"id": 15
},
...
]
}
COCO-WholeBody
This Github resource is the official repo for ECCV2020 paper "Whole-Body Human Pose Estimation in the Wild". The slides of this work can be found here. This repo contains COCO-WholeBody annotations proposed in this paper.
An example is:
{
"coco": {
"whole_body": [{
"screen_space_pos": [
0.28386247143569615,
0.6000729023148936
],
"name": "1",
"in_frustum": true,
"world_space_pos": [
-0.0939253717660904,
1.5864394903182983,
0.10542752593755722
],
"camera_space_pos": [
-0.08866584300994873,
-0.041052788496017456,
-0.20511440932750702
],
"id": 1
},
...
]
}
}Mediapipe
MediaPipe offers cross-platform, customizable ML solutions for live and streaming media.
MediaPipe Pose is a ML solution for high-fidelity body pose tracking, inferring 33 3D landmarks on the whole body from RGB video frames utilizing BlazePose research that also powers the ML Kit Pose Detection API.
MediaPipe Hands is a high-fidelity hand and finger tracking solution. It employs machine learning (ML) to infer 21 3D landmarks of a hand from just a single frame. Where some approaches rely primarily on powerful desktop environments for inference, MediaPipe Hands achieves real-time performance on a mobile phone, and even scales to multiple hands.
An example is:
{
"mediapipe": {
"body": [{
"screen_space_pos": [
0.3334939093552558,
0.6354655226675615
],
"name": "mouth_right",
"in_frustum": true,
"world_space_pos": [
-0.0844690278172493,
1.5460090637207031,
0.06293512880802155
],
"camera_space_pos": [
-0.08561654388904572,
-0.0696556493639946,
-0.2570973336696625
],
"id": 10
},
...
]
}
}
MPEG-4 Face and Body Animation (MPEG-4 FBA)
MPEG-4 Face and Body Animation (MPEG-4 FBA) is the part of MPEG-4 International Standard (ISO14496) dealing with animation of human or human-like characters. MPEG-4 FBA specifies:
- a set of 86 Face Animation Parameters (FAPs) including visemes, expressions and low-level parameters to move all parts of the face;
- a set of feature points on the face for any application that needs well-defined facial landmarks (e.g. facial feature detection in visage|SDK™ uses it to return feature coordinates);
- a set of 196 Body Animation Parameters (BAPs) consisting of joint rotation angles;
- efficient encoding of animation parameters resulting in full animation at very low bitrates (e.g. <5 kbps for face animation).
All Visage Technologies’ products which are levered by Synthesis.ai are based on MPEG-4 FBA, enabling standardised integration of modules and interchange with other 3rd party products.
Read more about MPEG-4 Face and Body Animation. See the MPEG-4 Reference Table below for feature points and recommended location constraints.
An example is:
{
"mpeg4": [{
"screen_space_pos": [
0.5393820673771856,
0.6215508733862406
],
"name": "2.13",
"in_frustum": true,
"world_space_pos": [
0.021466292440891266,
1.5507371425628662,
0.07281715422868729
],
"camera_space_pos": [
0.020612776279449463,
-0.06362035125494003,
-0.2617025673389435
],
"id": 2.13
},
...
]
}
EXR File
The exr has many channels, which are also automatically extracted to other asset files which can be downloaded as well.
| Channel Name | Description | Example Value |
|---|---|---|
|
RGBA |
Beauty pass with alpha |
 |
|
Z |
Z depth Min/max is zero to 100 meters. Black = 0 meters White = 100 (or infinite) meters Z-depth reference range is included in following outputs: EXR Header ‘zmin', 'zmax’ info.json Under ‘render’ inside ‘zmin’ and ‘zmax’ values **Image has been level adjusted to see value ranges in thumbnail. |
 |
|
CameraNormals.RGB |
Gives you the surface normal at the point being sampled, in camera coordinate space. The "surface normal" is a vector that points directly away from the surface (at right angles to it) at that point. |
 |
|
CameraPoints.RGB |
Gives you the position of the point being sampled, in camera coordinate space. |
 |
|
defocusAmount |
The defocusAmount (Defocus Amount) render element is non-black only when depth of field and motion blur are enabled, and contains the estimated pixel blurring in screen space. Required pass when denoising is enabled. |
 |
|
denoiser.RGB |
The VRayDenoiser render element, when generated, contains the final image that results from noise removal. Similar to effectsResults, but without lens effects added. Required pass when denoising is enabled. |
 |
|
diffuse.RGB |
The Diffuse Render Element shows the colors and textures used in materials, flatly applied to objects with no lighting information. |
 |
|
diffuse_hair.RGB |
Diffuse render element for hair elements |
 |
|
effectsResults.RGB |
Denoised beauty pass. Required pass when denoising is enabled. |
 |
|
noiseLevel |
The noiseLevel (Noise Level) render element is the amount of noise for each pixel in greyscale values, as estimated by the V-Ray image sampler. Required pass when denoising is enabled. |
 |
|
normals.XYZ |
The Normals Render Element creates a normals image from surface normals in the scene. It stores the camera space normal map using the geometry's surface normals. |
 |
|
rawDiffuseFilter.RGB |
The Raw Diffuse Filter Render Element is similar to the Diffuse Render Element, except it is not affected by Fresnel falloff. The result is a solid mask showing the pure diffuse color as set in the V-Ray Material's settings. |
 |
|
reflectionFilter.RGB |
The Reflection Filter Render Element stores reflection information calculated from the materials' reflection values in the scene. Surfaces with no reflection values set in its material(s) will contain no information in the render pass and will therefore render as black. |
 |
|
refractionFilter.RGB |
The Refraction Filter Render Element is an image that stores refraction information calculated from the materials' refraction values in the scene. Materials with no refraction values appear as black, while refractive materials appear as white (maximum refraction) or gray (lesser amounts of refraction). |
 |
|
worldNormals.XYZ |
The Normals Render Element creates a normals image from surface normals in the scene. It stores the world space normal map using the geometry's surface normals. |
 |
|
worldPositions.XYZ |
It stores the world space surface positions. |
 |
|
surface |
mask of all surfaces in the scene excluding skin. combined with the following surface.skin mask, it will be a mask of everything in the scene |
 |
|
surface.skin |
masks objects labeled as “skin” |
 |
|
segmentation.mustache |
mask for mustache only. does not include beard portions |
 |
|
segmentation.jaw |
 |
|
|
segmentation.hair |
mask for head hair only. does not include other hairs including mustache, bearch, eyebrows, etc. |
 |
|
segmentation.eyelid |
 |
|
|
segmentation.neck |
 |
|
|
segmentation.eye_right |
 |
|
|
segmentation.glasses_lens |
 |
|
|
segmentation.jowl |
 |
|
|
segmentation.mouth |
 |
|
|
segmentation.clothing |
 |
|
|
segmentation |
empty pass for creation |
|
|
segmentation.eyes |
 |
|
|
segmentation.ear_left |
 |
|
|
segmentation.teeth |
||
|
segmentation.cheek_right |
 |
|
|
segmentation.cheek_left |
 |
|
|
segmentation.eyelashes |
 |
|
|
segmentation.lip_upper |
 |
|
|
segmentation.chin |
 |
|
|
segmentation.shoulders |
 |
|
|
segmentation.nose_outer |
 |
|
|
segmentation.head |
 |
|
|
segmentation.eye_left |
 |
|
|
segmentation.beard |
 |
|
|
segmentation.mouthbag |
||
|
segmentation.glasses_frame |
 |
|
|
segmentation.lip_lower |
 |
|
|
segmentation.tongue |
||
|
segmentation.brow |
 |
|
|
segmentation.undereye |
 |
|
|
segmentation.ear_right |
 |
|
|
segmentation.nose |
 |
|
|
segmentation.smile_line |
 |
|
|
segmentation.temples |
 |
|
|
segmentation.nostrils |
 |
|
|
segmentation.forehead |
 |
|
|
segmentation.mask |
 |
|
|
binary_segmentation |
empty pass for creation |
|
|
binary_segmentation.foreground |
Masks objects labeled as “foreground”. Replaces Alpha as a way to separate the character from the background. |
 |
Mpeg4 Reference Table
| Feature points | Recommended location constraints | |||
|---|---|---|---|---|
|
# |
Text description | x | y | z |
|
2.1 |
Bottom of the chin | 7.1.x | ||
|
2.2 |
Middle point of inner upper lip contour | 7.1.x | ||
|
2.3 |
Middle point of inner lower lip contour | 7.1.x | ||
|
2.4 |
Left corner of inner lip contour | |||
|
2.5 |
Right corner of inner lip contour | |||
|
2.6 |
Midpoint between f.p. 2.2 and 2.4 in the inner upper lip contour | (2.2.x+2.4.x)/2 | ||
|
2.7 |
Midpoint between f.p. 2.2 and 2.5 in the inner upper lip contour | (2.2.x+2.5.x)/2 | ||
|
2.8 |
Midpoint between f.p. 2.3 and 2.4 in the inner lower lip contour | (2.3.x+2.4.x)/2 | ||
|
2.9 |
Midpoint between f.p. 2.3 and 2.5 in the inner lower lip contour | (2.3.x+2.5.x)/2 | ||
|
2.10 |
Chin boss | 7.1.x | ||
|
2.11 |
Chin left corner | > 8.7.x and < 8.3.x | ||
|
2.12 |
Chin right corner | > 8.4.x and < 8.8.x | ||
|
2.13 |
Left corner of jaw bone | |||
|
2.14 |
Right corner of jaw bone | |||
|
3.1 |
Center of upper inner left eyelid | (3.7.x+3.11.x)/2 | ||
|
3.2 |
Center of upper inner right eyelid | (3.8.x+3.12.x)/2 | ||
|
3.3 |
Center of lower inner left eyelid | (3.7.x+3.11.x)/2 | ||
|
3.4 |
Center of lower inner right eyelid | (3.8.x+3.12.x)/2 | ||
|
3.5 |
Center of the pupil of left eye | |||
|
3.6 |
Center of the pupil of right eye | |||
|
3.7 |
Left corner of left eye | |||
|
3.8 |
Left corner of right eye | |||
|
3.9 |
Center of lower outer left eyelid | (3.7.x+3.11.x)/2 | ||
|
3.10 |
Center of lower outer right eyelid | (3.7.x+3.11.x)/2 | ||
|
3.11 |
Right corner of left eye | |||
|
3.12 |
Right corner of right eye | |||
|
3.13 |
Center of upper outer left eyelid | (3.8.x+3.12.x)/2 | ||
|
3.14 |
Center of upper outer right eyelid | (3.8.x+3.12.x)/2 | ||
|
4.1 |
Right corner of left eyebrow | |||
|
4.2 |
Left corner of right eyebrow | |||
|
4.3 |
Uppermost point of the left eyebrow | (4.1.x+4.5.x)/2 or x coord of the uppermost point of the contour | ||
|
4.4 |
Uppermost point of the right eyebrow | (4.2.x+4.6.x)/2 or x coord of the uppermost point of the contour | ||
|
4.5 |
Left corner of left eyebrow | |||
|
4.6 |
Right corner of right eyebrow | |||
|
5.1 |
Center of the left cheek | 8.3.y | ||
|
5.2 |
Center of the right cheek | 8.4.y | ||
|
5.3 |
Left cheek bone | > 3.5.x and < 3.7.x | > 9.15.y and < 9.12.y | |
|
5.4 |
Right cheek bone | > 3.6.x and < 3.12.x | > 9.15.y and < 9.12.y | |
|
6.1 |
Tip of the tongue | 7.1.x | ||
|
6.2 |
Center of the tongue body | 7.1.x | ||
|
6.3 |
Left border of the tongue | 6.2.z | ||
|
6.4 |
Right border of the tongue | 6.2.z | ||
|
7.1 |
top of spine (center of head rotation) | |||
|
8.1 |
Middle point of outer upper lip contour | 7.1.x | ||
|
8.2 |
Middle point of outer lower lip contour | 7.1.x | ||
|
8.3 |
Left corner of outer lip contour | |||
|
8.4 |
Right corner of outer lip contour | |||
|
8.5 |
Midpoint between f.p. 8.3 and 8.1 in outer upper lip contour | (8.3.x+8.1.x)/2 | ||
|
8.6 |
Midpoint between f.p. 8.4 and 8.1 in outer upper lip contour | (8.4.x+8.1.x)/2 | ||
|
8.7 |
Midpoint between f.p. 8.3 and 8.2 in outer lower lip contour | (8.3.x+8.2.x)/2 | ||
|
8.8 |
Midpoint between f.p. 8.4 and 8.2 in outer lower lip contour | (8.4.x+8.2.x)/2 | ||
|
8.9 |
Right hiph point of Cupid’s bow | |||
|
8.10 |
Left hiph point of Cupid’s bow | |||
|
9.1 |
Left nostril border | |||
|
9.2 |
Right nostril border | |||
|
9.3 |
Nose tip | 7.1.x | ||
|
9.4 |
Bottom right edge of nose | |||
|
9.5 |
Bottom left edge of nose | |||
|
9.6 |
Right upper edge of nose bone | |||
|
9.7 |
Left upper edge of nose bone | |||
|
9.8 |
Top of the upper teeth | 7.1.x | ||
|
9.9 |
Bottom of the lower teeth | 7.1.x | ||
|
9.10 |
Bottom of the upper teeth | 7.1.x | ||
|
9.11 |
Top of the lower teeth | 7.1.x | ||
|
9.12 |
Middle lower edge of nose bone (or nose bump) | 7.1.x | (9.6.y + 9.3.y)/2 or nose bump | |
|
9.13 |
Left lower edge of nose bone | (9.6.y +9.3.y)/2 | ||
|
9.14 |
Right lower edge of nose bone | (9.6.y +9.3.y)/2 | ||
|
9.15 |
Bottom middle edge of nose | 7.1.x | ||
|
10.1 |
Top of left ear | |||
|
10.2 |
Top of right ear | |||
|
10.3 |
Back of left ear | (10.1.y+10.5.y)/2 | ||
|
10.4 |
Back of right ear | (10.2.y+10.6.y)/2 | ||
|
10.5 |
Bottom of left ear lobe | |||
|
10.6 |
Bottom of right ear lobe | |||
|
10.7 |
Lower contact point between left lobe and face | |||
|
10.8 |
Lower contact point between right lobe and face | |||
|
10.9 |
Upper contact point between left ear and face | |||
|
10.10 |
Upper contact point between right ear and face | |||
|
11.1 |
Middle border between hair and forehead | 7.1.x | ||
|
11.2 |
Right border between hair and forehead | < 4.4.x | ||
|
11.3 |
Left border between hair and forehead | > 4.3.x | ||
|
11.4 |
Top of skull | 7.1.x | > 10.4.z and < 10.2.z | |
|
11.5 |
Hair thickness over f.p. 11.4 | 11.4.x | 11.4.z | |
|
11.6 |
Back of skull | 7.1.x | 3.5.y |